Filtering Non-Devanagari Words: A Heuristic-based Approach
When collecting Nepali text corpus, we usually collect it from various online sources such as Wikipedia, News portals, and other websites. The online sources introduce a lot of errors due to imperfect online tools such as translators, font convertors, spelling checker, etc. Some of these errors include typos, spelling mistakes, foreign words, incorrect symbols. Dealing with these errors poses a challenging task. In this post, we will look at a simple heuristic-based algorithm to filter Non-Devanagari words from a Nepali corpus.
The Devanagari Unicode Range
In Unicode, the Devanagari characters are included in the range U+0900 to U+097F, as shown in the figure below.
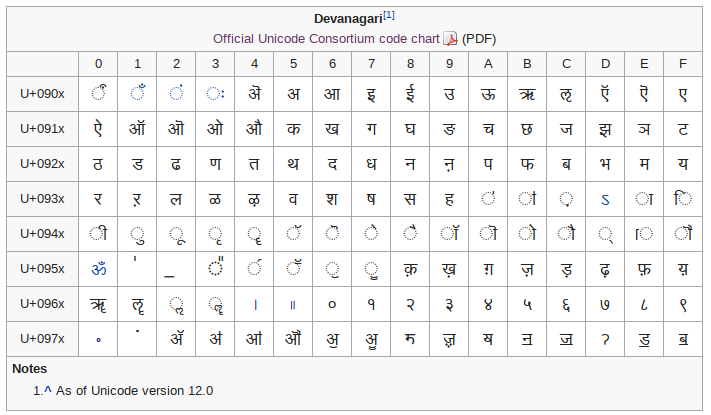 |
|---|
| Source: Wikipedia |
The Algorithm
In our algorithm, we will check the individual characters of a token whether they belong to the Devanagari Unicode range or not. For this will use this regular expression [\u0900-\u097F\\].
Then, we will keep count of the Devanagari characters.
The algorithm uses a simple heuristic: does majority of characters in a token belong to the Devanagari range or not. If it does, then token is a Devanagari word, else not.
Pseudo Code
for token in sentence
if majority of characters in token belong to Non-Devanagari
token is not in Devanagari script
else
token is in Devanagari script
This algorithm classifies words with punctuations to Devanagari as oppose to an algorithm that checks if the token consists of Non-Devanagari characters.
Limitations
One of the major limitations of the procedure is that it removes the Non-Devanagari words rendering the sentence incorrect/incomplete.
Implementation
import re
devanagari_range = r'[\u0900-\u097F\\]'
def getDevanagariCharCount(token):
return len(list(filter(lambda char: re.match(devanagari_range, char), (char for char in token))))
def isDevanagari(token):
return True if getDevanagariCharCount(token) >= len(token)/2 else False
def filterTokens(line):
return list(filter(lambda t: isDevanagari(t), line.split(" ")))
sentence = "मलाई उपन्यास पढ्न, trekking जान र फूतball खेल्न मन लाग्छ।"
filtered = filterTokens(sentence)
print(filtered)
# Output
# मलाई उपन्यास पढ्न, जान र खेल्न मन लाग्छ।"